Tackling Data Gaps: Essential Python Techniques for Handling Missing Values

Source: Joyce 2023.
Minding the gap is not just a caution. It is a critical imperative. Businesses that ignore missing values risk stumbling into a gap of uncertainty. Incomplete data does not just obscure the truth; it can derail decision-making, stifle innovation, and ultimately threaten a company's success. To thrive in today’s data-driven landscape, organizations must confront these gaps head-on and transform them into opportunities for insight.
Python provides various techniques for tackling the threat posed by missing values. This article will explore three of these Python techniques.
Why Remove Missing Values?
Missing values are not just values missing in datasets. Its impact is far-reaching. For instance, a business with gaps in its dataset cannot accurately predict its future, preventing it from potentially taking advantage of potential insights for decision-making. Neither can such a business sustain or defend its strategic position effectively, lacking crucial information.
Handling missing values provides businesses the chance to improve their operations and the opportunity to adapt new approaches to work, possibly unlocking innovative ideas and strategically positioning themselves.
What are missing values?
The absence of a data value in an observation is referred to as a null value. Data analysts often encounter null values during the data analysis process, and these can significantly skew conclusions drawn from datasets.
Missing values can exist in an observation for various reasons. Incomplete data entry, equipment malfunctions, system migration, system integration and lost files are a few of the reasons. In addition, there are different types of missing values, requiring that each missing value be placed in context to inform any necessary actions.
This article will consider omission and imputation methodologies. Omission involves removing samples with invalid data from rows that might have less impact on the analysis. Imputation includes filling in missing data with a value such as the mean and the median of a variable. Omission might be suitable when missing data is minimal, while imputation could be better when retaining data is crucial.
Additionally, advanced imputation techniques, which are not the subject of this article but are worth mentioning, such as K-Nearest Neighbors (KNN) and iterative imputation offer more sophisticated ways to handle missing data. KNN estimates missing values based on the similarity between data points, while iterative imputation uses relationships among multiple variables to fill in gaps. Multiple imputation, which generates several complete datasets to account for uncertainty, can also enhance the robustness of data analysis.
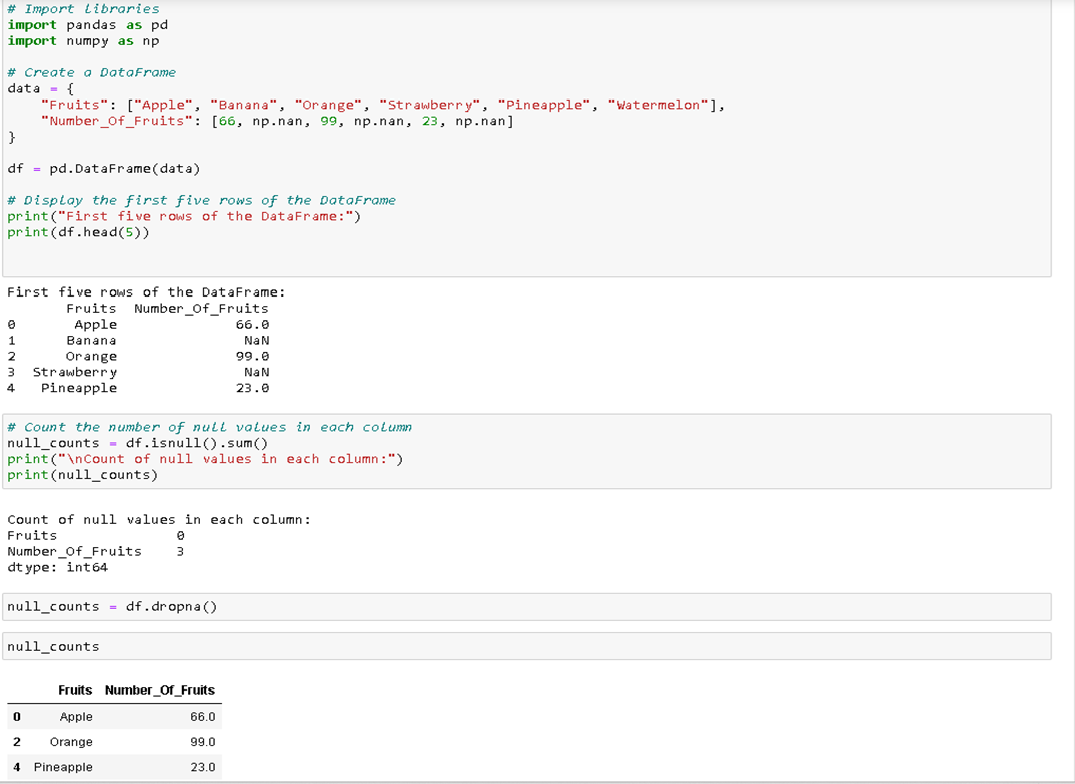
Let's explore how omission can be applied to a dataset using Python. We'll start with a DataFrame that contains some missing values.
Source: Joyce 2023.
In this example, the initial DataFrame contains six rows, with some missing values in the "Number_Of_Fruits" column. By applying the dropna() method, we remove rows with null values, resulting in a clean DataFrame with three rows. This process illustrates how omission can effectively clean a dataset, making it ready for further analysis without the noise of missing data.
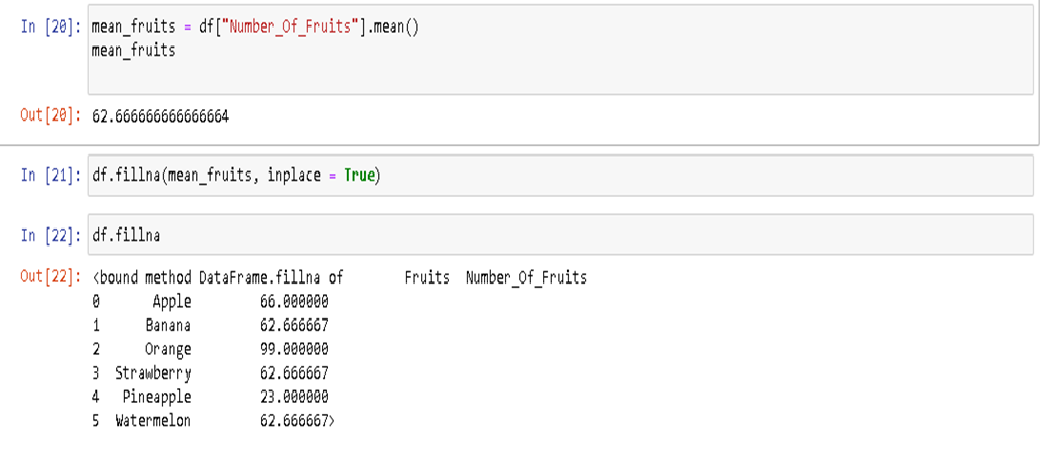
Next, we will discover how to replace missing values with the mean. Let’s begin by finding the mean of the Number-of-Fruits variable
Source: Joyce 2023.
In this illustration, all three missing values have been replaced with the mean value, using the fillna() method. With no missing values, we have a complete table, depicting how the imputation technique can become an effective cleaning method for preprocessing data. The three charts below illustrate the impact of each methodology on cleaning data.
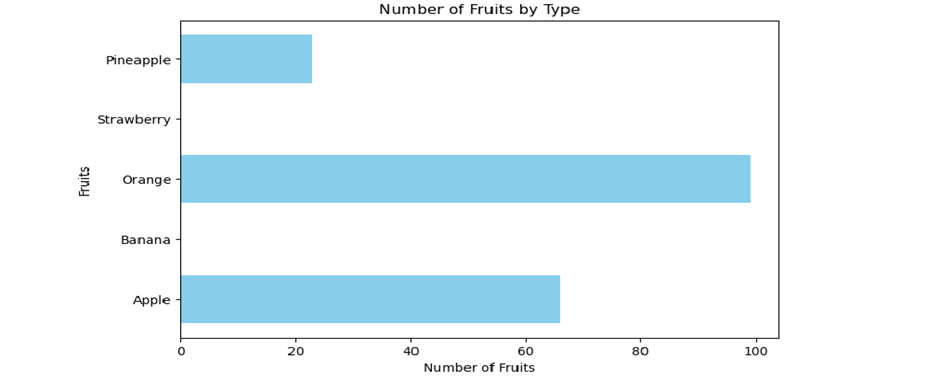
This first chart visualizes the original dataset, where missing values are present. Grey bars indicate NaN values, showing gaps in the data. This visualization helps identify the extent of missing data and underscores the need for data cleaning. In real-world datasets, such gaps can lead to incomplete analyses and skewed insights if not addressed properly. Understanding these effects is crucial for selecting the appropriate data-cleaning method based on the specific context and requirements of your analysis.
Chart 1: Missing Data
Source: Joyce 2023.
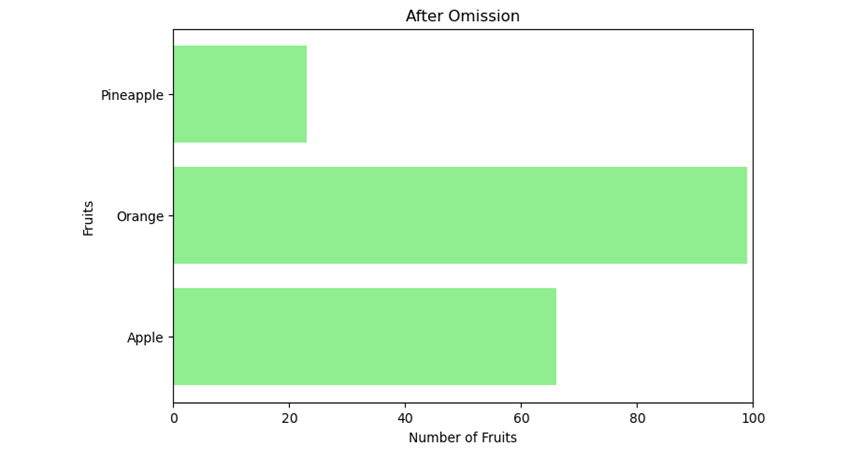
The second chart demonstrates the effect of the omission methodology. Here, rows with missing values are effectively removed, leaving only the complete data entries. This approach is useful when the missing data is minimal and unlikely to affect the overall analysis significantly. However, it can also result in the loss of potentially valuable information, especially if a large portion of the dataset is discarded.
Chart 2: After Omission
Source: Joyce 2023.
The third chart illustrates the imputation technique, where missing values are replaced with the mean of the available data. This method allows for the retention of all data entries, ensuring a complete dataset for analysis. Imputation can be particularly beneficial when missing data is substantial, as it maintains the dataset's integrity while providing a reasonable estimate for the missing values. However, it's important to choose the imputation method carefully, as it can introduce bias if not appropriately applied. By comparing these charts, you can see how each technique impacts the dataset. Omission simplifies the dataset by removing incomplete entries, while imputation fills
Chart 3: After Imputation
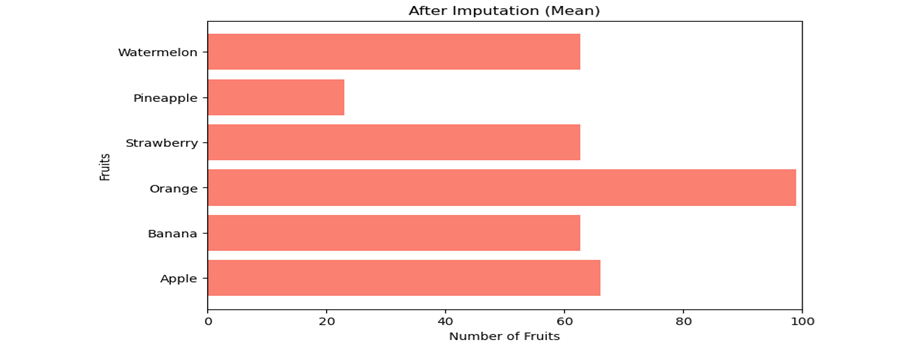
Source: Joyce 2023.
In conclusion, gaps in a dataset can significantly hinder a business's ability to fully leverage its data. Addressing missing values is crucial for transforming incomplete data into actionable insights. This article has demonstrated how techniques such as omission and imputation can effectively clean and enhance data quality. By applying these methodologies, businesses can bridge the gaps in their data and unlock its full potential, enabling them to make informed decisions and tell a complete story with their data. To automate your data cleaning process, you can use our Data Cleaning Tool: “The Lazy Man’s Kit. Visit Data Cleansing Tool:"The Man's Tool"